|
|
|
|
Thanks for all the good times last week virtual and in person. We had some fun!
|
|
|
|
|
|
|
From Arduinos to Large Language Models: Exploring the
Spectrum of Machine Learning
Tiny ML refers to very small machine learning devices, like Arduino Nano, with only a few kilobytes of RAM. These devices must hold both the model and the code to run and execute it, read data from sensors, and process it.
Now, add on the complexity of running the damn thing remotely using only battery power.
In this episode, we got to sit down with an absolute legend and talk tinyML and large language models. Even if no one chants his name today, they will be in the future. (Go to your nearest yoga class and tell me they don't chant his name).
Soham discusses his work on TinyML for a medicine manufacturer
and his thoughts on the challenges of using large language models at scale.
We also hear his thoughts on the downfalls of prompt engineering and the challenges that come with it, including the reliance on OpenAI and the issues with scalability and reliability.
|
|
|
|
|
|
|
Things were happening a few weeks ago in Bristol! Valerio Maggio talked about the magic of PyScript - a tool that allows Python to interact directly with JavaScript in web browsers.
Valerio breaks down Piadite, which is the powerhouse PyScript is built with.
At the end of his talk, he does a deep dive into the architecture of PyScript, how it works with packages and dependencies, and how it can be deployed as easily as an HTML file.
Of course, no live meetup would be complete without a demo. In this case, Valerio shows off Pythrive.com and the PyCharm plugin that supports PyScript.
|
|
|
|
|
|
|
LLMs have taken the world by storm. Given their powerful functionalities, these models have ingrained themselves into our everyday activities. Yet, we must not overlook the fact that the technology is largely owned by the "big tech" companies, requiring organizations and individuals to transfer all their sensitive data to centralized third parties.
I recently spoke with Simone, one of the founders of Prem, about why they created the tool.
"My life’s passion has been around the same question for a long time: How do we
preserve our sovereignty and privacy in the age of AI? Back in 2016, I was part of a research project promoted by the Institute of Data Driven Design and MIT media lab called Data Common - where we developed a GDPR-compliant platform.
A few months ago, with the release of ChatGPT, AI hit the mainstream, and privacy challenges escalated. Ironically, out of all countries, Italy was the first to deny access to OpenAI back in March.
I dug into terms and conditions and saw how my data was being used to train their models, raising a few red flags with the algorithm being closed source and Microsoft's involvement."
We created a Privacy-centric
AI platform. Prem offers a unified secure environment to develop AI applications and deploy AI models on your infrastructure with a single click.
We wanted to make it easy and let people use tools they already know, like Langchain, Llamaindex, and vector stores. This way, you can create Generative AI apps that you are entirely in control of.
To begin your journey with Prem, download Prem App, or use the API. Simone and the team are actively seeking community help to improve this open-source project.
If you are passionate about advancing AI privacy and want to contribute to the movement actively, join the Prem community.
Discord — https://discord.gg/QcApYCFyWr
Twitter — https://twitter.com/premai_io
GitHub — https://github.com/premAI-io/prem-app
|
|
|
|
|
|
|
|
|
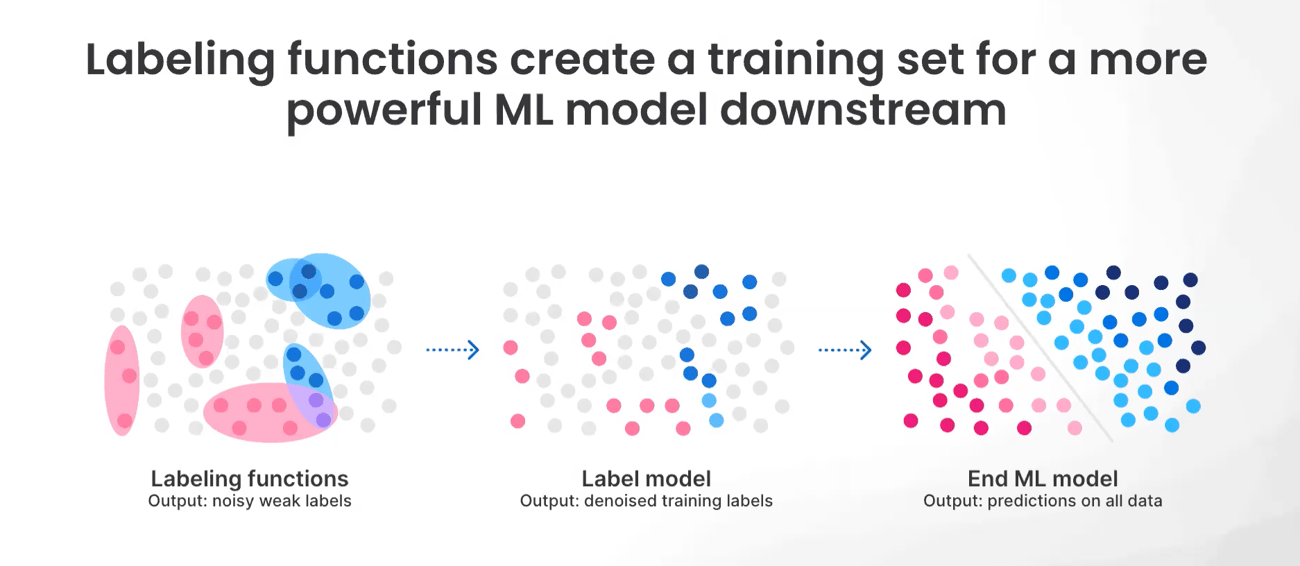
Unlock LLMs with programmatic labeling
Even with the rapid advancements to AI made possible by LLMs and Foundation Models, data remains the key to unlocking real value for enterprise AI.
During this live demo, Snorkel AI co-founder and head of technology, Braden Hancock, will show you how Fortune 500 AI/ML teams utilize their data as the key differentiator when building high-performing production models with Snorkel.
You’ll see how Snorkel Flow:
- Accelerates AI development with programmatic labeling, a fundamentally more scalable approach to building and maintaining high-quality datasets
- Enables utilizing existing resources (noisy labels, models, ontologies, etc.), domain expert heuristics, embeddings, foundation models, and more to improve label quality
- Can be used to distill LLM knowledge into a smaller, efficient model or to fine-tune an existing foundation model like GPT-3
- Can use LLM knowledge with zero- and few-shot learning to auto-label training data with a push of a button
Save Your Spot
|
|
|
|
|
From now on we will highlight one awesome job per week! Please reach out if you want your job featured.
|
|
|
|
|
|
|
|
|
Thanks for reading. This issue was written by Demetrios and edited by
Jessica Rudd. See you in Slack, Youtube, and podcast land. Oh yeah, and we are also on Twitter if you like chirping birds.
|
|
|
|
|