|
|
|
|
If we can do one thing better in the community what would it be? Reply back.
|
|
|
|
|
|
|
MLOps and the Age of Generative AI // Barak Turovsky
Barak Turovsky, a former product manager at Google and a Google Translate team member, now invests in ML/AI companies that aim to change the world.
Let's discuss Barak's differentiation between yellow and red AI use cases. Yellow use cases, where users can double-check for accuracy, are better suited for LLMs. Examples are creating content such as writing, music, and business presentations. Red use cases, such as search queries and important business decisions (e.g., loan scoring), cannot be validated by users and require more time for LLMs to become commonplace in the industry. Raise your hand if you are doing fraud detection with LLMs……🤷♂️
Barak has created a framework for effectively using large language models based on his experience with Google Translate. Keep in mind that Google Translate was already experimenting with LLMs
before the hype. Thanks to his team, every gringo in Mexico could be 10 times more obnoxious (myself included... or should I say, "a mi también").
Back on topic, he stressed the importance of considering fluency vs. accuracy and high-stakes vs. low-stakes factors when determining the applicability of LLMs. We also discussed my favorite topic, the challenges of hallucinations. Did I mention we have a shirt?
Links below to listen. We are dangerously close to reaching 100 reviews on Spotify. Will you be that special somebody to get us there? Neptune AI, Piotr, shares his insights on the importance of confidence and control in production, the need for regulations and audits, and the significance of order and reproducibility in engineering processes.
He also discusses Neptune's mission to provide ML/AI teams with the same level of control and confidence in building and testing models as in software development.
According to everyone that's used the, large language models still have many challenges when using them in production. Much of Piotr’s brain power has been focused on discovering and supporting ways to test and validate new LLMs.
We also chat about “classical” machine learning vs. deep learning, the role of AutoML, and the use of numerical methods to test and validate models.
|
|
|
Job of the week
ML Infra Engineer at Slack - The tool this community knows and loves is looking to bring on more MLOps peeps.
The ML Services team, part of Slack’s Core Infrastructure organization, is responsible for delivering the platform, infrastructure, and expertise in ML/AI to make this product vision possible.
They’ve built out much of this already as part of their Recommendation API, which you can read about here, but the needs of foundational AI models, with their unique development model and architectural needs, will require even further investment in their capabilities. They’re looking to hire machine learning infrastructure engineers who can help deliver on that mission.
|
|
|
|
|
|
|
|
|
Deployment Issues
I love this article so much. It zooms in on one of the most
important pieces of the ML/AI landscape at the moment.
How do I know this is top of mind for the community right now?
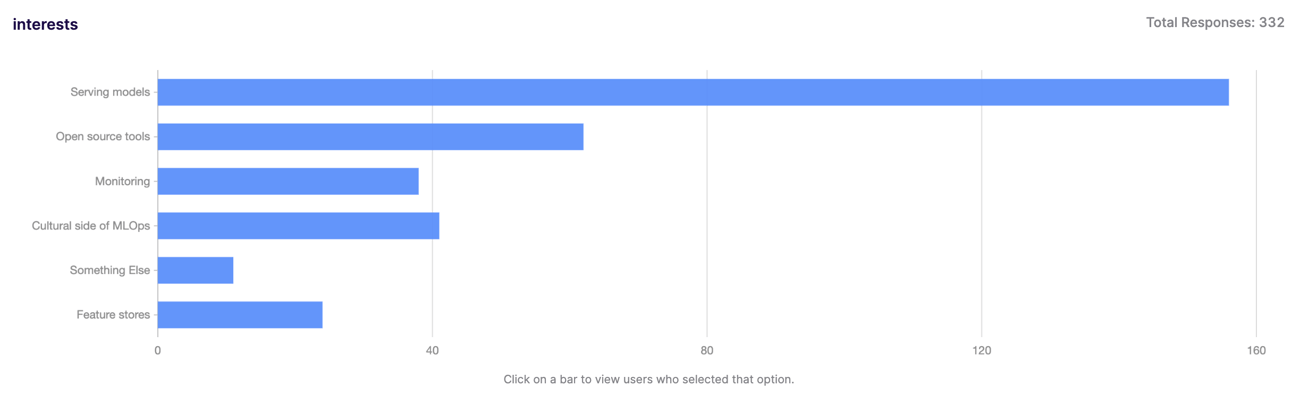
Each person who joins Slack is given the option to go through an onboarding bot walkthrough where they are asked pre-defined questions.
If you identify as a practitioner (as opposed to a vendor) you are asked which topic you most want to learn about. The photo above shows the responses over the last 6 months.
"A Shift in ML Deployment" might as well be called, GPUs are all you need because, damn, the space is heating up. Let's look at some of my takeaways:
- The traditional ML deployment model is wack, yo. The process of building
and deploying ML models is becoming increasingly complex. Top that off with soaring demand for ML-powered applications, and boom, perfect storm.
- The new ML deployment model is more iterative and collaborative. This is because data scientists and DevOps engineers need to work together closely to ensure that models are deployed correctly and meet the business's needs.
- The increasing availability of cloud computing platforms and tools makes the new model possible. Cloud computing platforms provide a scalable and cost-effective environment for deploying ML models. In addition, several tools can help data
scientists and DevOps engineers automate the deployment process.
- Developer experience is crucial. Data scientists have not been properly spoiled, leading them not to understand that things do not need to be as painful as they have been. “Why wouldn't you want to replace all those steps with one click? It's not that hard to do.” …. um, can you say Stockholm syndrome? (Okay, this was my own observation, not from the article.)
|
|
|
|
|
|
|
From MLOops to MLOps: LLMs & Stable Diffusion in the Cloud
In this episode, we had the pleasure of hosting Alex Payot, who shared valuable insights from his experience providing deep learning models to users on cloud platforms.
Alex emphasized the importance of engineers adopting a product mindset and genuinely caring about the user experience and customer needs. After all, a successful ML project is not just about the technology; it's about meeting real-world requirements.
Alex delves into
the responsibilities of ML engineers, highlighting the significance of validation approaches and ensuring the relevancy of models. They stress the importance of training stability and maintaining reliable operations around the model. From managing change logging and monitoring systems to keeping artifacts in sync with the team, it's clear that a meticulous approach is necessary for success in the MLOps realm.
Some key points covered were:
- Challenges faced when dealing with overlaid file systems
- The importance of having a written and repeatable process
- Questions around the process of Continuous Integration (CI) and large data transfers
- The benefits of design wrappers for tools, particularly when dealing with large file uploads
- Where to automate to save time and improve efficiency
- The complexities of managing artifacts and automating data collection
- The difficulties encountered when analyzing the behavior of machine learning models
- The goal of providing a seamless AI
experience for first-time users
Check out the in-person talk here, and if you want to go to a live event, check our meetup page to see if we have a local chapter around you.
Video
|
|
|
|
|
|
|
My man, Bojan Jakimovski, shares his journey of transforming his data science team's productivity by introducing some MLOps into the mix.
This whole blog started as a thread in the discussions channel on Slack and then morphed into an artifact that many can learn from. Love it when that happens.
Here's a summary of the key points covered:
Challenges Faced: fragmented data storage, lack of data versioning, limited user access control, manual data processing, inefficient experiment tracking, and complex model deployment.
Centralized and Easily Accessible Data Storage: The team tackled the issue of
fragmented data storage by implementing a centralized repository using AWS S3. They organized data into phases (raw, raw_aligned, processed, and experiment data) to establish a clear data transformation pipeline.
Data Versioning and User Groups: Data governance was enhanced by enabling data versioning on AWS S3 and implementing user groups with specific access permissions using AWS IAM, improving data security and integrity.
Streamlined Data Transformation Pipeline: Automated data transformation pipeline for each data phase significantly reduced manual errors and accelerated data processing using AWS Lambda Functions and AWS Sagemaker Processing.
Centralized MLflow Server for Experiment Tracking: They established a centralized MLflow server on AWS EC2 to
improve experiment tracking and model management. They added security layers through Nginx reverse proxy and basic authentication to safeguard data and models.
Deploying Models with ML Batch Serverless Inference: The team operationalized models using a custom microservice—ML batch serverless inference—combining various AWS services for efficient deployment in production environments.
The list goes on but I just hit the word limit on this email. Check out the link for all the details.
Read Now
|
|
|
|
|
Add your profile to our jobs board here
|
|
|
|
|
|
|
|
|
Thanks for reading. This issue was written by Demetrios and edited by Jessica Rudd. See you
in Slack, Youtube, and podcast land. Oh yeah, and we are also on Twitter if you like chirping birds.
|
|
|
|
|