|
|
|
|
Our incredible 2-day AI in Production conference is all wrapped up, and videos are coming soon!
Next, we're aiming bigger: 4 days, Paris Expo Porte De Versailles, 10+ tracks of keynotes and sessions. But wait, KubeCon + CloudNativeCon Europe got there first - and it all goes live 19-22 March in Paris!
But, the great news is, the Linux Foundation have kindly reached out to offer a special discount for members of the MLOps Community: 15% off passes*!
Enter code MLOPS_KUBECON at checkout and see amazing speakers like Timothée Lacroix, co-founder of Mistral. And how do I know he’s an amazing speaker? Because he wowed us as a key speaker at our LLMs in Production event! Managed to beat KubeCon to that one!
*Yeah, Ts&Cs apply I’m afraid! 15% off applies to All Access or KubeCon + CloudNativeCon passes (corporate or individual). Entrance only, travel and accommodation not included.
|
|
|
|
|
|
|
Information Retrieval & Relevance: Vector Embeddings for Semantic Search // Daniel Svonava // MLOps Podcast #214
Seeing me struggle to understand vector compute was not a pretty picture. But, Daniel used a metaphor about cameras to explain, and then it ‘clicked’!
He walked me through crafting user data vectors from raw info, ditching biases from the get-go. He mentioned these vectors sharpen recommendations for different scenarios during retrieval or inference and make model training smoother. He also got in to the potential applications of vector embeddings technology, like
analytics for customer behavior, machine maintenance and business intelligence queries.
A great snapshot of vector compute!
|
|
|
Got Unstructured Data and Don’t Know Where to Start? - supported by Zilliz Cloud Pipelines
|
|
|
|
|
|
|
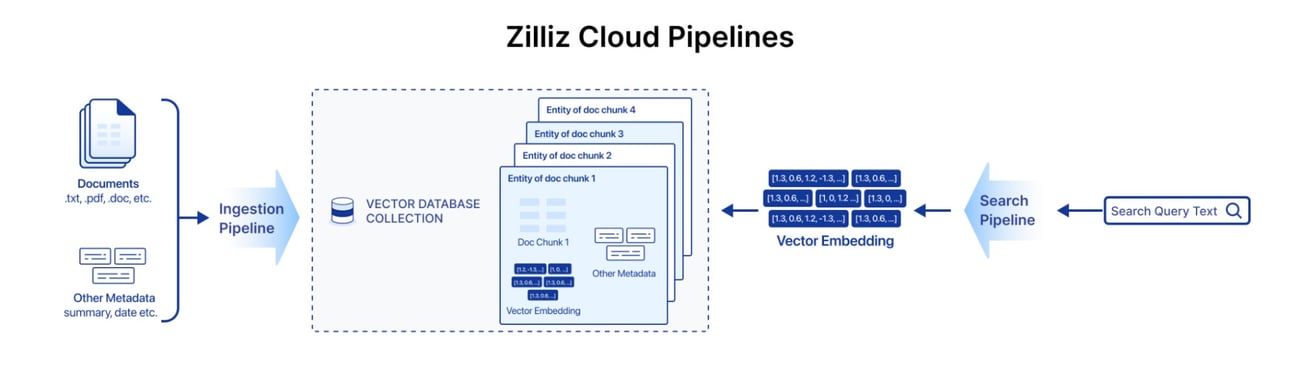
As creators of the open source vector database Milvus, one of the most common questions we hear from the AI community is, “how do I convert my unstructured data into vector embeddings?” or “which embedding model should I use to convert my data into vectors?”. If you’ve struggled with these same issues, you’re in luck.
Zilliz Cloud Pipelines enables you to choose from different embedding models from providers like OpenAI, BAAI, and Voyage AI, build data pipelines to convert your unstructured text data into high-quality embeddings, and ingest them into a vector database. Zilliz Cloud Pipelines streamlines building semantic text search and retrieval augmented generation (RAG) applications.
To help new users get started, we put together this notebook that walks you through creating a simple RAG application from start to finish.
|
|
|
AI in Production Keynote Speaker
|
|
|
|
|
A Survey of Production RAG Pain Points and Solutions // Jerry Liu
Had to throw in a bit from the AI in Production conference...
RAGs are all the rage, but how do you get RAG applications production-ready?
Well, this talk looks at how challenges like scaling, pipeline creation, optimizing multiple parameters for accuracy in software, the need for improving retrieval of context based on user queries and the struggles with structured outputs.
Thankfully, he shares solutions like appropriate document parsing and setting up recurring data ingestion pipelines, so you don't have to struggle!
Keep your eye out for more conference videos being released to help you get in to
production!
|
|
|
💡Job of the weekSenior Machine Learning Engineer // Yahoo News (US,
Remote)
An opportunity to build the models and systems that will power a completely reimagined presentation of news at Yahoo to its 35 million daily users.
Responsibilities:
- Hands-on development
of “full-stack” ranking, recommendation and content understanding systems.
- Leverage third-party, open-source and in-house machine learning tools to build high-performing machine learning systems.
- Work collaboratively with cross-functional partners to leverage machine learning
to improve Yahoo News for our readers and build state-of-the-art tooling for our editorial team.
Requirements:
We're assembling a team skilled in machine learning engineering, modeling, or data engineering. Join us for a full-stack ML challenge if you have expertise in one of these domains:
- ML Engineering: Experience in deploying ML models and knowledge of MLOps required.
- ML Modeling: Ability to solve product problems with ML frameworks and differentiate between research and production code.
- Data Engineering: Strong in data engineering principles and proficient in Python, Java, Scala, or Go.
|
|
|
|
|
|
|
125+ awesome folks took our last survey, but we're aiming for a stellar 300 this time!
We're already at 100 cool people on board, but the more insights, the merrier, right?
This quick survey goes beyond just models, diving into use cases, metrics, and datasets. A few minutes to answer, but a lasting impact on evaluation insights!
Take the survey here!
|
|
|
MLOps Community IRL Meetup
|
|
|
|
|
Surf the Next Wave of Innovation // IRL Meetup #66 Stockholm
A look at an ML workbench, emphasizing its lifecycle approach to machine learning, from data discovery through to deployment. Erik focused on the intricacies of managing LLMs, highlighting the need for fine-tuning and the interplay between classic ML techniques and LLMs. Using a RAG model, he also showcased voice-activated search and question-answering for a podcast. Great idea, just not sure if he picked the best podcast to use...
|
|
|
|
|
|
|
|
|
Start them young! Share your insights!
|
|
|
Audio Generation with Mamba using Determined AI
LLMs are great, but it's nice to
hear something else. Literally, hear something else.
This blog shares an experiment with Mamba, a new architecture for audio generation, using Determined AI for training. Mamba differs from traditional transformers by using State-Space Models for processing sequences efficiently. Isha details training Mamba on various audio datasets, challenges, insights gained, and some outputs the model was able to generate. With thanks to Isha Ghodgaonkar for their contribution.
|
|
|
|
|
Add your profile to our jobs board here
|
|
|
|
|
|
|
|
|
|
|
|
|